Spark(笔记)
spark运行模式:
- 本地模式
- standalone模式:独立集群(封闭)
- yarn模式:(开放)
- yarn-client:AM(driver)在提交任务的本地启动 (交互 / 调试方便)
- yarn-cluster:AM(driver)在某个NN上启动
cluster模式下,driver运行在AM中,负责向Yarn申请资源 ,并监督作业运行状况,当用户提交完作用后,就关掉Client,作业会继续在yarn上运行。然而cluster模式不适合交互类型的作业。而client模式,AM仅向yarn请求executor,client会和请求的container通信来调度任务,即client不能离开
spark运行模式区别:
- Spark standalone:独立模式,类似MapReduce1.0所采取的模式,完全由内部实现容错性和资源管理
- Spark on Yarn:让Spark运行在一个通用的资源管理系统之上,这样可以与其他计算框架共享资源
- Yarn Client:适用于交互与调试
- Driver在任务提交机上执行
- ApplicationMaster只负责向ResourceManager申请executor需要的资源
- 基于yarn时,spark-shell和pyspark必须要使用yarn-client模式
- Yarn Cluster:适用于生产环境
- Yarn Client:适用于交互与调试
- Yarn(通用)
- Master/Slave结构
- RM:全局资源管理器,负责系统的资源管理和分配
- NM:每个节点上的资源和任务管理器
- AM:每个应用程序都有一个,负责任务调度和监视,并与RM调度器协商为任务获取资源
- Standalone(Spark自带)
- Master/Slave结构
- Master:类似Yarn中的RM
- Worker:类似Yarn中的NM
- Master/Slave结构
验证Spark
- 本地模式: –]# ./bin/run-exampleSparkPi10--master local[2]
- 集群模式Spark Standalone: –]# ./bin/spark-submit--classorg.apache.spark.examples.SparkPi--masterspark://master:7077 lib/spark-examples-1.6.0-hadoop2.6.0.jar 100
- 集群模式Spark on Yarn集群上yarn-cluster模式: –]# ./bin/spark-submit--classorg.apache.spark.examples.SparkPi--masteryarn-clusterlib/spark- examples-1.6.0-hadoop2.6.0.jar 10
Hadoop中:
一个MapReduce程序就是一个job,MapReduce中的每个Task分别在自己的进程中运行,当该Task运行完时,进程也就结束
Spark中:
spark中一个任务是多个job
- Application:spark-submit提交的程序
- Driver(AM):完成任务的调度以及和executor和cluster manager进 行协调
- Executor:每个Spark executor作为一个YARN容器 (container)运行
Executor:真正执行task的单元,一个Work Node上可以有多个Executor
- Job:和MR中Job不一样。MR中Job主要是Map或者Reduce Job。而Spark的Job其实很好区别,一个action算子就算一个Job,比方说count,first等
- Task:是Spark中最小的执行单元。RDD一般是带有partitions 的,每个partition在一个executor上的执行可以认为是一个Task
- Stage:是spark中独有的。一般而言一个Job会切换成一定数量 的stage。各个stage之间按照顺序执行
- Stage概念
Spark任务会根据RDD之间的依赖关系,形成一个DAG有向无环图,DAG会提交给DAGScheduler,DAGScheduler会把DAG划分相互依赖的多个stage,划分stage的依据就是RDD之间的宽窄依赖。遇到宽依赖就划分stage,每个stage包含一个或多个task任务。然后将这些task以taskSet的形式提交给TaskScheduler运行。 stage是由一组并行的task组成。
- stage切割规则
切割规则:从后往前,遇到宽依赖就切割stage。
spark中:
- 应用程序:由一个driver program和多个job构成
- job:由多个stage组成
- Stage:对应一个taskset
- Taskset:对应一组关联的相互之间没有shuffle依赖关系的组成(1对1不是shuffle依赖)
- Task:任务最小的工作单元
-
Shuffle的含义就是洗牌,将数据打散,父RDD一个分区中的数据如果给了子RDD的多个分区(只要存在这种可能),就是shuffle。Shuffle会有网络传输数据,但是有网络传输,并不意味着就是shuffle。
-
窄依赖:没有发生shuffle
-
宽依赖:存在shuffle
Driver Program:
- (驱动程序)是Spark的核心组件
- 构建SparkContext(Spark应用的入口,创建需要的变量,还包含集群的配置信息等)
- 将用户提交的job转换为DAG图(类似数据处理的流程图)
- 根据策略将DAG图划分为多个stage,根据分区从而生成一系列tasks
- 根据tasks要求向RM申请资源
- 提交任务并检测任务状态
Spark Core
- Spark是计算框架
- Spark-Core是基础框架,可以支持批量+实时(流式计算)
MR也是一个计算框架(批量)
spark速度快,MR速度慢(MR中间环节数据结果是落地的 => 经过磁盘交换)
Spark计算过程主要的数据流转由内存完成(减少了对HDFS的依赖)- MR:多进程模型:
- 优点:进程之间隔离,任务更加稳定
- 缺点:每个任务启动时间长,不适合低延迟任务 API抽象简单,只有map和reduce两个原语
- Spark:多线程模型
- 优点:速度快,适合低延迟,开发成本低
- 缺点:稳定性差
AM向RM申请的是executor资源,executor都是装载在container里运行,executor启动后,由spark的driver(AM)向executor分配task,分配多少task、分配到哪个executor由AM决定,可理 解为spark也有个调度过程,Executor维护了一个线程池多线程管理这些task
启动spark任务涉及的参数:
- executor-memory:每个executor内存多大
- num-executors:多少个executor进程
- executor-cores:每个executor有多少个core
Spark解决了什么问题?
- 最大化利用内存cache
- 中间结果放内存,加速迭代
- 某结果集放内存,加速后续查询和处理,解决运行慢的问题
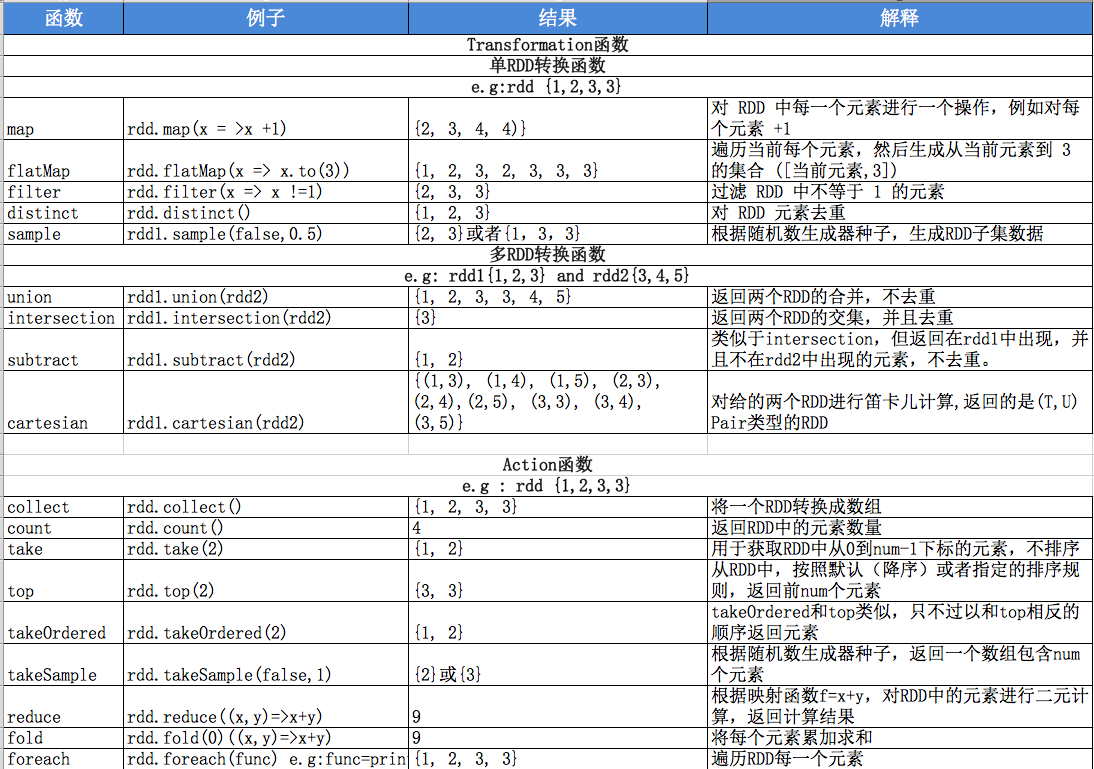
Spark算子:

- Transformation:转换算子 => 并不触发提交作业,完成作业中间过程处理
- Transformation操作是延迟计算 — 懒惰机制
- RDD 转换生成另一个RDD的转换操作,并不是马上执行,只有遇到Action操作的时候,才会真正的触发运算
- Transformation操作是延迟计算 — 懒惰机制
Transformation算子细分:
单独对v处理:(value)
- 一对一:map ,flatMap
- 多到一:union ,cartesion(笛卡儿积)
spark不支持unionall,union=unionall ——— spark的union不去重
- 多对多:groupby
- 输出是输入的子集合:filter,distinct
- cache类:cache,persist
k-v形式:(key -> value)
- 一对一:mapValues
- 单个聚集(RDD):reduceByKey,combineByKey,PartitionBy
- 两个聚集(RDD):cogroup
- 连接:join,lefOutJoin,rightOutJoin
- Action:行动算子 => 触发(SparkContext)提交作业,并将数据输出Spark系统(hdfs,hbase,kafka,console)
Action算子细分:
进一步细分:
- 无输出: foreach
- 有输出:saveAsTextFile(存到HDFS)
- 统计类:count,collect,take(取top {$n})